Kürzlich stand bei einem Kunden folgende Fragestellung im Raum ...
"Welche der bestehenden NC-Maschinen ist für unsere intern und extern gefertigten Artikel die "Richtige", um optimale Fertigungszeiten, minimale Rüstkosten und eine hohe Effizient zu erreichen"?
Ziel des Projektes war die Sicherstellung der Versorgungssicherheit bei optimalen Kosten innerhalb des Firmenverbunds und die Sicherung von Standorten/Arbeitsplätzen durch optimale Auslastung.
Die zu beantwortenden Fragen waren:
- Welche Zerspanungsmaschine ist für welche Bauteile optimal geeignet?
- Welche Artikel kann das Unternehmen bei gegebenem Maschinenpark selbst fertigen?
- Welche Artikel können intern kostenoptimierter gegenüber den Lieferanten hergestellt werden?
- Welche fertigungstechnischen Skills werden optimal an einem Standort gebündelt
- Wie werden eingekaufte Artikel optimal auf die Lieferanten aufgeteilt?
Ausgangslage
- Ca. 68'000 verschiedene Artikel, welche intern und extern gefertigt werden - mit sehr hoher Varianz in der geometrischen Ausprägung.
- Drei verschiedene Standorte, an welchen Bauteile gefertigt werden
- 36 Mio. Einkaufsvolumen (Make)
- Unterschiedlichste Zerspanungsmaschinen (3 Achsen, 5 Achsen, etc.)
Welche Maschine ist für welche Artikel geeignet?
Normalerweise braucht es zur Beantwortung obiger Fragestellung zuerst mal Expertenwissen ... den die Mitarbeiter, welche die Maschinen kennen und bedienen wissen genau, welche Bauteile am besten geeignet sind. Dieses Vorgehen ist - bei verschiedensten Maschinen, in verschiedensten Ländern bei vielen Mitarbeitern - nicht adäquat. Aufwand, Projektdauer und Ertrag stehen nicht im Verhältnis. Die Herausforderung "schreit" geradezu nach Algorithmen.
Wenn Machine Learning übernimmt
Wenn Machine Learning zum Zug kommt braucht es Daten. Ob intern oder extern gefertigte Artikel ... von den meisten Bauteilen bestehen 3D CAD Modelle und 2D Zeichnungen. Zudem ist aufgrund der Produktionsplanung bekannt, welche Artikel zum heutigen Zeitpunkt auf welcher Maschine gefertigt werden. Das ist schon viel Wissen ... und vor allem sind das viele Daten! Die 3D Modelle enthalten viel Wissen zur Geometrie und Ausprägung. Das Data-Mining mit der Data-Driven Engine kann losgehen. 2D Zeichnungen sind wichtig um alle Genauigkeitsangaben zu den Artikeln zu erfahren. Auch hier hilft die Data-Driven Engine mit dem 2D CADminer. In tausenden 3D CAD Daten und 2D Dokumenten werden alle relevanten Parameter automatisiert ausgelesen. Welche Laufzeiten die Bauteile auf den Maschinen hatten ist vorerst nicht relevant. Es geht in erster Linie darum, Transparenz zu schaffen und Artikel zu identifizieren, welche aufgrund Ihrer Ausprägung nicht in das "Artikelspektrum pro Maschine" passen.
Make or Buy?
Die Fragestellung "Make or Buy" steht immer wieder zuoberst auf der Liste vieler Unternehmen. Im Zuge der Analyse zur Teileallocation konnte diese Frage für 68'000 Artikel auch gleich beantwortet werden. Es wurden nicht nur Artikel, welche intern gefertigt wurden, in die Analyse miteinbezogen. Auch Artikel die eingekauft wurden, sind dem Data-Mining unterzogen und analysiert worden. Die Erkenntnisse liegen anschliessend pro Warengruppe vor. Ob Drehen, Fräsen, Schleifen ... die Transparenz nach der Massendaten Analyse ist nicht zu übertrumpfen. Im folgenden Bild (Warengruppe Drehteile Edelstahl, unbeschichtet) ist das Verdikt klar. Die interne Fertigung ist deutlich teurer als externe Lieferanten, welche ähnliche Bauteile fertigen.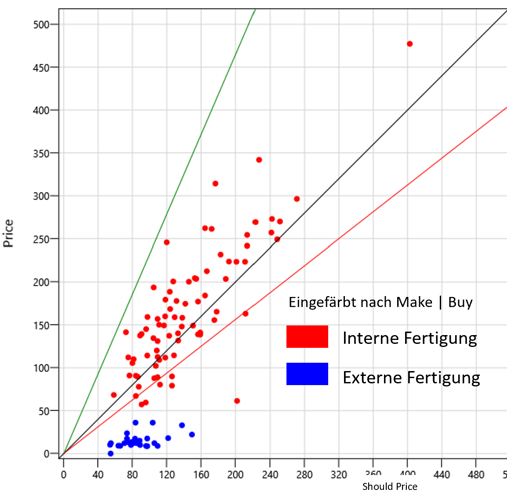
Machine Learning schlägt vor, auf welcher Maschine Artikel gefertigt werden sollen
Algorithmen und Machine Learning sind bestens geeignet Vorhersagen zu treffen (unsupervised learning). Bei unserem Kunden übernehmen im neuen Jahr Algorithmen die Teileanalysen in Echtzeit und erstellen Vorschläge zur optimalen Maschine - in Bezug auf Rüstzeiten, Laufzeiten und Effizienz. Natürlich gibt es noch weitere Parameter, die auf eine optimale Platzierung zielen. Auch diese Parameter fallen schrittweise in die Entscheidungsfindung ein. Das spart unserem Kunden substanziell Zeit und Geld. Und die Nutzung der Daten geht noch weiter ... natürlich klassifizieren unsere Algorithmen die Artikel vollautomatisch in die vom Kunden definierten Warengruppen (ACM - adaptive category management) und die Kosten der Bauteile werden auch gleich berechnet - mit Data-Driven Costing. Ihre Unternehmensdaten haben einen immensen Wert. Machen Sie was draus!